2020年02月03日
全国には102の地域銀行がある。同じ地域銀行といえども、各行の収益モデルは一様ではないはずだが、一つ一つの銀行の決算データを見るのはなかなか時間と労力がかかる。「銀行の決算データを一つ一つ見ることなく、収益構造ごとに銀行を分類したい」、「特徴的な収益構造を持つ銀行を見つけたい」、そのようなときに便利な手法としてクラスタリングというものがある。クラスタリングとはおおざっぱに述べると、AIによるデータをもとにしたグループ分けである(詳細は参考欄を参照)。
では、実際にやってみるとどうなるか。今回は地域銀行の中でも地方銀行(全国地方銀行協会加盟行64行)に限って、2018年度決算における主要な経常収益・費用項目のデータを機械に学習させて、分類した。なお、本来は収益構造を見る場合、複数年度のデータを考慮することが望ましいが、ここでは簡単な例として単年度のデータを取り上げる。
図表1はクラスタリングにおけるグループ分けの過程と結果を表したものである。縦軸がそれぞれの銀行の距離(どれだけ似ていないか)を示しており、高い位置で分岐しているものほど「似ていない」ことを意味する。言い換えると低い位置で分岐しているものは「似ている」銀行どうしである。分類の結果、8つのグループに分かれており、うちグループ①~③は複数の銀行が含まれている。グループ④~⑧はそれぞれ1行ずつしか含まれていないため、どこともあまり似ていない収益構造を持つ銀行であると判断されたことが分かる。特にグループ⑧の銀行は最も高い位置で分岐しており、他の銀行とは大きく異なった決算内容であったことが示唆されている。

AIが分類したグループ別に2018年度の決算内容を平均して示したものが図表2である。図表中の下部に記した通り、各グループに特徴があることが見て取れる。また、1行ずつ分類されたグループ④~⑧の銀行は、比較的大きな債券売却損や株式等売却益の発生、多額の貸倒引当金の計上などにより、特異な動きをしていることが分かる。クラスタリングの結果としては、概ね各地方銀行の特徴を捉えたグループ分けができたといえるのではないか(字数の関係で本文中では割愛したが、本来は平均だけでなく分布等も確認する必要がある。)。
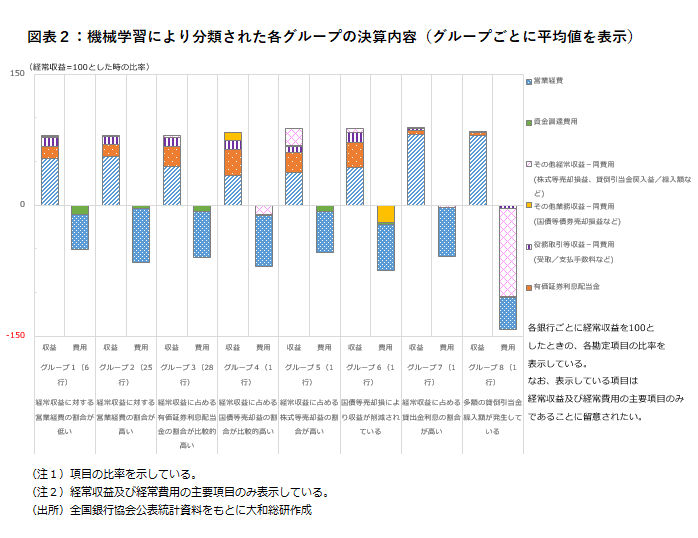
なお、クラスタリングは距離の決め方やグルーピングの方法が多数あり、方法を変えれば、分類結果も変わるため、結果は絶対的なものではない。注意点はあるものの、このようにクラスタリングによって収益構造の特徴をおおまかに掴むことができれば、債券利回りや貸出金利、株価の変動をもって、どの銀行が大きく影響を受けるかといったことも考えやすくなる。また、特徴的な動きをしている銀行を素早く見分けることができるため、そこから該当する銀行の動向を精査し新たな知見を得ることもできるだろう。
より正確に各銀行のビジネスモデルの違いを捉えるには、単年度でなく、複数年にわたる収益構造の推移や資産・負債の内容や規模も考慮すべきであるが、それらは今後の課題としたい。
参考:クラスタリングとは
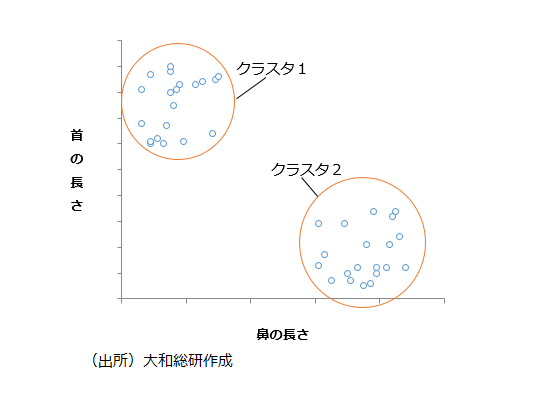
与えられたデータから規則性や判断基準を機械が学習し、これに基づき未知のものを予測、判断する技術を機械学習と呼ぶ。クラスタリングは機械学習の手法の一つである。クラスタリングでは、分類の答えが与えられない状態で、モデルが各サンプルの特徴量をもとに似ているものを集めてグループ分けを行う。例えば、キリンとゾウの首の長さと鼻の長さを測ったデータがあるが、どちらの動物か種類の区別がつかない状態であるとする。データをもとにクラスタリングにより2つに分類すると下図のようになる。モデルはキリンとゾウの特徴について学習していなくとも、データからサンプル間の距離(どれだけ近い/離れているか)を判断して、キリンとゾウを別々のグループに分類できる。判断基準を与えずともデータをもとに分類できるため、本コラムのように明確な区分のないものを分類したいといった場面において有用である。
このコンテンツの著作権は、株式会社大和総研に帰属します。著作権法上、転載、翻案、翻訳、要約等は、大和総研の許諾が必要です。大和総研の許諾がない転載、翻案、翻訳、要約、および法令に従わない引用等は、違法行為です。著作権侵害等の行為には、法的手続きを行うこともあります。また、掲載されている執筆者の所属・肩書きは現時点のものとなります。
- 執筆者紹介
-
経済調査部
研究員 中田 理惠





