




「いつ、何が起こるか」を予測することは、ビジネスにおける重要な意思決定です。顧客の解約時期や設備の故障時期、患者の予後といった「時間軸を含む予測」は、適切な施策のタイミングを決めるうえで価値があります。このようなイベント発生までの期間を分析する手法を「生存時間解析」と呼びます。従来の生存時間解析の統計モデルは、予測結果の根拠を説明しやすい(解釈性に優れる)一方で、複雑なデータ構造や高次元の特徴量を十分に扱えない場面がありました。
近年、ITの発展により、企業が収集できる時系列データが飛躍的に拡大しました。機械学習技術の進展により、これらのデータから複雑なパターンを抽出し、精緻な予測が可能になっています。生存時間解析の分野では、従来の統計的手法の限界を超え、機械学習モデルの適用が進んでいます。
本記事では、生存時間解析の基礎から機械学習手法による実装、そして実践的な応用までを解説します。技術的な詳細と実務での活用可能性のバランスを考慮しながら、このアプローチがもたらす価値を紐解きます。
第1章:生存時間解析とその意義
1.1 生存時間解析とは
生存時間解析 (Survival Analysis) は、イベントが発生するまでの期間を対象とした統計分析手法です。医療分野における患者の生存期間分析から発展しましたが、現在では金融、製造、マーケティング、人事などさまざまな分野で活用されています。
生存時間解析の基本的な考え方
生存時間解析の特徴は、「打ち切り」と呼ばれる不完全なデータを統計的に正しく扱える点にあります。顧客の解約予測を例にとると、観察期間中に解約しなかった顧客のデータも分析に活用できます。従来の予測モデルでは「解約した/しない」という二値で判断しがちですが、生存時間解析では「いつまで継続したか」という時系列情報を保持したまま分析を進められます。
例えば、サブスクリプションサービスで1年間観察した場合を考えます。
- 顧客A:契約後3カ月で解約
- 顧客B:契約後8カ月で解約
- 顧客C:1年経過しても継続中
従来の二値分類モデルでは、顧客Aと顧客Bを単に「解約」として同じカテゴリに分類し、顧客Cを「継続」として扱います。しかし、顧客Aと顧客Bでは解約までの期間が大きく異なり、その背景にある要因も異なる可能性があります。また、顧客Cについても「解約しない」と断定できるわけではなく、観察期間を超えて継続しているだけかもしれません。
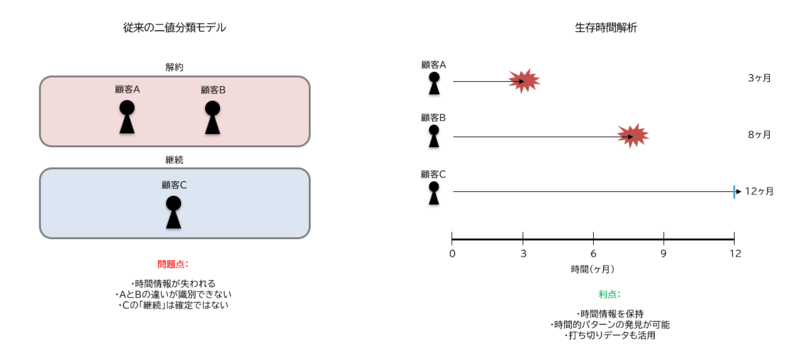
生存時間解析では、従来の二値分類と異なり、各時点でのリスクや継続確率を算出できます。これにより「3カ月目にリスクが高まる」といった時間的パターンの発見が可能になり、打ち切りデータも「少なくとも1年間は継続した」という価値ある情報として活用できます。
なぜ時間軸が重要なのか
「何が起こるか」だけでなく「いつ起こるか」を知ることで、介入や対策の最適なタイミングを特定できます。リスクが高まる時期を事前に予測できれば、効果的な施策を適切なタイミングで実施でき、単なる「起こる・起こらない」の二値予測よりも実用的な戦略立案が可能になります。
1.2 生存時間解析が注目される背景
生存時間解析が注目を集めている背景には、技術の進化とビジネス環境の変化という2つの大きな要因があります。
データの多様化と機械学習の進化
デジタル化により、企業は顧客行動、設備稼働状況、取引履歴など、膨大な時系列データを蓄積できるようになりました。IoTセンサー、Webサイトの行動ログ、SNSデータなど、データの種類も多様化しています。
従来の統計的手法(Cox比例ハザードモデルなど)は解釈性が高い一方で、線形性や比例ハザード性などの仮定により、複雑なデータへの対応に限界がありました。機械学習技術の発展により、これらの制約を超えた高精度な予測が可能になっています。
ビジネス環境の変化と意思決定の高度化
競争環境の流動性が増す現代では、企業は迅速かつ精緻な判断が求められています。消費者ニーズの変動サイクルは短縮し、新規サービス投入のペースも速まっています。過去のデータから未来を予測するだけでなく、「いつ、どのような変化が起こるか」を予測することが競争優位性の源泉となります。
1.3 各分野における活用事例
生存時間解析は金融・医療・製造・マーケティング・人事など、多様な分野で実務に活用されています。以下では、各分野における具体的な応用シーンを紹介します。
金融分野での活用事例
顧客リレーションシップの最適化
金融機関にとって、取引先との持続的なつながりは事業基盤の根幹です。生存時間解析により、顧客の取引継続期間を予測し、解約リスクの早期検知、セグメント別のLTV(ライフタイムバリュー)推定、個々の顧客に適したタイミングでのパーソナライズ提案など、効果的なリテンション施策の実現が期待されます。信用リスク評価の高度化
従来の信用リスク評価では、「デフォルトする確率」の予測が中心でした。生存時間解析により「いつデフォルトが発生しやすいか」という時間的視点を加えることで、動的なリスク管理、ポートフォリオの最適化など、時間軸を考慮したリスク管理手法の確立が期待されます。
製造分野での活用事例
- 設備保全の最適化
機械の稼働データから故障時期を予測し、計画的な保全を実施することで、突発的な故障による生産停止を防げます。部品の経年変化データに基づき交換タイミングを見極め、保管費用の最適化を図ることも可能です。また、製品の不良が発生する時期を予測し、製造工程の改善に活用する品質管理への応用も進んでいます。
医療・ヘルスケア分野での活用事例
疾病リスク予測と予防医療
健康診断データや医療レセプトデータを活用し、疾病発症時期の予測、個別化された健康管理プログラムの提案、医療費の適正化など、予防医療の実現が期待されます。健康保険組合や企業の健康管理部門と連携することで、データの持つ時間的な情報を最大限に活用し、従来のスクリーニング手法では見逃されがちだった中長期的なリスクも捉えることが可能になります。治療効果の評価と医療資源の最適配分
治療法ごとに再発までの期間を比較し、エビデンスに基づいた医療を推進できます。また、患者の入院期間を予測することで、病床管理やスタッフ配置を効率化し、医療資源の最適配分が可能になります。
人事分野での活用事例
- 従業員のウェルビーイングと生産性向上
高齢化の進展にともない、企業における健康経営・人的資本経営への関心が高まっています。従業員の健康データや人事データを活用したデータ分析において、生存時間解析の手法を取り入れることで、従業員の離職予測が可能になります。健康状態の変化や働き方のパターンから、従業員が離職や健康問題に直面する可能性が高まるタイミングを予測し、その段階で個別フォローやキャリア支援を提供することで、従業員一人ひとりが最大限のパフォーマンスを発揮できる環境づくりが期待されます。
マーケティング分野での活用事例
- 顧客生涯価値(LTV)の算出とキャンペーン効果測定
顧客の継続期間と購買行動を統合的に予測し、投資判断を最適化できます。プロモーション実施後の反応継続期間を測定し、後続アクションの最適な実行時期を見極めることで、マーケティング施策の効果を最大化できます。
第2章:生存時間解析の基礎と機械学習の進化
2.1 生存時間解析の基本概念
生存時間解析を理解するには、いくつかの基本概念を押さえる必要があります。これらの概念は、時間軸を含むデータを適切に扱うための理論的な基盤となります。
生存関数(Survival Function)
生存関数 S (t) は、時刻 t の時点で事象が未発生である確率を示します。数式では S (t) = P (T > t) と表現されます。
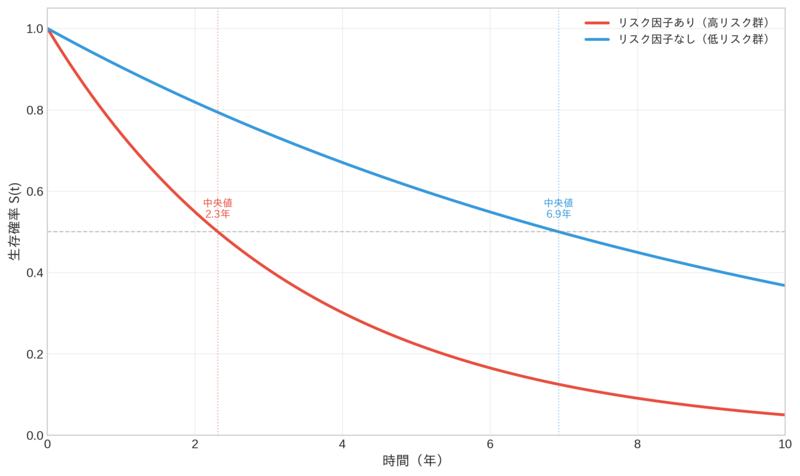
例えば、糖尿病発症リスク予測で S (5) = 0.85 であれば、「5年後の未発症確率が85%」と解釈できます。複数グループの生存関数を比較することで、リスクの差異を可視化できます。
出所: 大和総研作成
この図は、リスク因子を持つ群(赤線)と持たない群(青線)の生存関数を比較しています。リスク因子を持つ群では生存関数が急速に低下し、生存時間中央値が約2.3年であるのに対し、リスク因子を持たない群では約6.9年と約3倍の差があります。このように、生存関数を可視化することで、リスク因子の影響を直感的に理解できます。
生存関数の特性:
- 時刻 t=0 では S(0) = 1(開始時点では全員が「生存」している)
- 時間とともに減少する(または一定を保つ)
- t→∞ のとき、S(t)→0(十分に時間がたてば、いずれ事象が発生する)
ハザード関数(Hazard Function)
ハザード関数 h (t) は、時刻 t における事象発生の瞬間的リスクを示します。厳密には、「時刻 t まで事象が未発生という条件下で、時刻 t 直後に事象が起こる確率」を意味します。
例えば h (3) = 0.02/年 であれば、「3年経過時点で未発症の人が、その後1年間に発症する率が2%」と解釈できます。
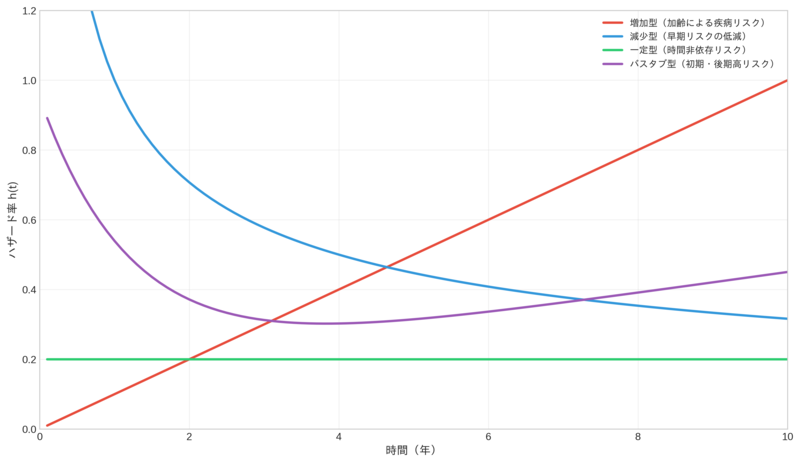
この図は、4つの異なるハザードパターンを示しています。実際のビジネスや医療データでは、さまざまなパターンが観察されます。例えば、生活習慣病では加齢とともにリスクが上昇する増加型、健康改善プログラムの効果は時間とともに減衰する減少型、遺伝的要因は時間に依存しない一定型、そして初期と後期にリスクが高まるバスタブ型などがあります。
ハザード関数は、リスクの時間的変化を捉えるのに有効です。
- 増加型ハザード:時間とともにリスクが高まる(例:加齢にともなう疾病リスク)
- 減少型ハザード:時間とともにリスクが下がる(例:健康改善プログラム後のリスク低減)
- 一定ハザード :時間によらず一定のリスク(例:遺伝的要因による疾病)
- バスタブ型ハザード:初期に高く、中期に低下し、後期に再び上昇(例:生活習慣病の発症パターン)
累積ハザード関数(Cumulative Hazard Function)
累積ハザード関数 H (t) は、時刻0から時刻tまでに蓄積されたハザードの総量を表現します。生存関数との関係は S (t) = exp (-H (t)) で示されます。
例えば H (5) = 0.8 であれば、S (5) = exp (-0.8) ≒ 0.45 となり、「5年後の未発症確率が45%」と解釈でき、予防介入の判断材料となります。
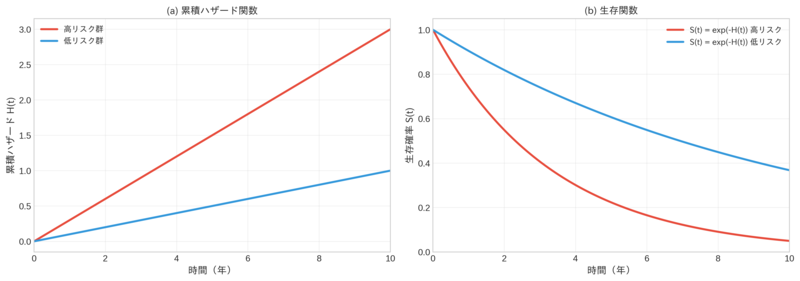
左図は累積ハザード関数を、右図は生存関数を示しています。累積ハザードは時間とともに単調増加し、リスクの蓄積を表します。S(t) = exp(-H(t))の関係式により、累積ハザードから生存関数を計算できます。高リスク群では累積ハザードの増加が急峻で、対応する生存関数は急速に低下します。この関係性を理解することで、どちらの視点からもデータを解釈できるようになります。
打ち切りデータ
打ち切りとは、観察期間中に事象が発生しなかったデータを指します。生存時間解析が他の統計手法と一線を画す最大の特徴が、この打ち切りデータの適切な扱いです。
打ち切りの種類
- 右打ち切り:最も一般的な形態。観察期間の終了時点で事象が発生していない
例:5年間の健康追跡調査で糖尿病を発症しなかった人 - 左打ち切り:観察開始前に事象が既に発生していた
例:初回健診時に既に疾病を発症していたが、正確な発症時期は不明 - 区間打ち切り:事象の発生時刻が区間としてしかわからない
例:年次健診の間に疾病が発症したが、正確な発症日は不明
- 右打ち切り:最も一般的な形態。観察期間の終了時点で事象が発生していない
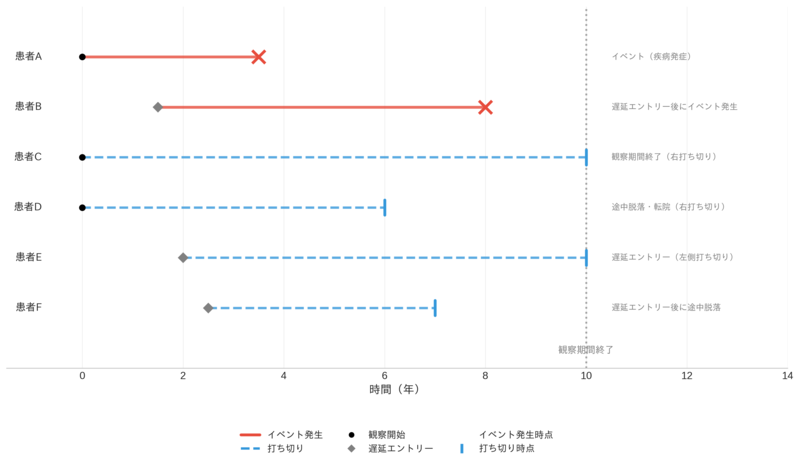
出所: 大和総研作成
この図は、生存時間解析で扱う主要な6つのパターンを視覚化しています。赤色の実線はイベント発生(×印で終了)、青色の破線は打ち切り(縦線で終了)を示します。患者Aは観察開始から3.5年でイベント発生、患者Bは研究開始後に参加(遅延エントリー、◆印)してから6.5年後にイベント発生しています。患者Cは10年間の観察期間終了まで未発症(観察期間終了による右打ち切り)、患者Dは6年目で追跡不能(途中脱落による右打ち切り)となっています。患者Eは2年目から参加し観察終了まで未発症(遅延エントリー)、患者Fは2.5年目から参加して7年目に脱落(遅延エントリー後脱落)しています。これらの多様なパターンを適切に扱えることが、生存時間解析の強みです。
なぜ打ち切りデータを無視してはいけないのか
従来の分類モデルで打ち切りデータを単に「未発症」として扱うと、以下の問題が生じます。
- 情報の損失:「1年追跡」と「10年追跡」を同じ「未発症」として扱うと、追跡期間の違いという重要な情報が失われる
- バイアスの発生:打ち切りデータを除外すると、早期に発症したケースのみが分析対象となり、リスクを過大評価する
- 予測精度の低下:不完全ながらも価値のある情報(「少なくとも○年間は未発症だった」)を活用できない
生存時間解析では、カプラン・マイヤー推定量 (Kaplan-Meier estimator) (注1)やCox比例ハザードモデルの部分尤度(ゆうど)(注2)などの統計的に適切な手法により、打ち切りデータから最大限の情報を抽出します。
(注1)Kaplan, E. L., & Meier, P. 「Nonparametric Estimation from Incomplete Observations」 Journal of the American Statistical Association, 53(282), 457-481 (1958)
https://www.tandfonline.com/doi/abs/10.1080/01621459.1958.10501452
(注2)Cox, D. R. 「Regression Models and Life-Tables」 Journal of the Royal Statistical Society: Series B (Methodological), 34(2), 187-220 (1972)
https://www.jstor.org/stable/2985181
生存時間中央値(Median Survival Time)
生存時間中央値は、生存関数が0.5になる時点、すなわち「半数の対象が事象を経験する時期」を表します。
例えば、生存時間中央値が7年なら、「ハイリスク者の半数が7年以内に発症する」ことを意味し、予防介入の優先順位付けや効果測定の基礎となります。
2.2 生存時間解析における機械学習モデル
従来手法から機械学習へのパラダイムシフト
1972年にDavid Coxにより提唱されたCox比例ハザードモデルは、生存時間解析における「ゴールドスタンダード」として長年使用されてきました。このモデルは以下の特徴を持ちます。
Coxモデルの利点:
- 統計的に洗練された理論に基づく(ベースラインハザードをパラメトリックに仮定する必要がない)
- 解釈性が高く、各変数の影響を定量化しやすい
- 比較的少ないサンプルサイズでも安定した推定が可能
Coxモデルの制約:
- 線形性の仮定:変数とハザードの対数の間に線形関係を仮定
- 比例ハザード性:各変数のハザード比への影響が時間によって変化しないと仮定
- 交互作用の明示的指定:変数間の相互作用を事前に指定する必要がある
- 高次元データへの対応困難:変数の数がサンプル数に近づくと推定が不安定になる
現代のビジネスデータは、これらの仮定を満たさないことが多々あります。例えば、顧客の解約リスクは、契約初期と長期継続後では異なる要因に影響されるかもしれません(比例ハザード性の違反)。また、複数のマーケティング施策が組み合わさった効果は、単純な加算では表現できない可能性があります(非線形性・交互作用)。
機械学習モデルの概要
生存時間解析に機械学習を適用する研究が進んでおり、以下のようなモデルが開発されています。各モデルには特徴があり、分析目的やデータの性質に応じて使い分けることが重要です。
| モデル | 適している事例・分析 | 主な強み |
|---|---|---|
| Random Survival Forest (RSF) |
|
過学習に強く、並列処理が可能で大規模データにも対応 |
| Gradient Boosting Survival Tree (GBST) |
|
予測精度が高く、変数重要度も算出可能 |
| DeepSurv |
|
複雑な非線形関係を学習でき、多様なデータ形式に対応 |
出所: 大和総研作成
Random Survival Forest (RSF)
2008年にIshwaranらによって提唱されたモデル(注3)で、ランダムフォレストを生存時間解析に拡張したものです。各決定木(データを条件によって分岐させながら予測を行う手法)が打ち切りデータを考慮しながら分岐を決定し、複数の木の予測を集約することで生存関数を推定します。
主な特徴:
- 複数の決定木を組み合わせることで、複雑な非線形関係を捕捉
- 変数重要度を算出でき、どの要因が予測に寄与しているかを把握可能
- 変数間の交互作用を自動的に学習
- 過学習に対して比較的ロバスト
- 並列処理が可能で、大規模データにも適用しやすい
課題:
- 多数の決定木を保持するため、モデルサイズが大きくなる
- 個々の決定木の解釈が難しい(集約モデルのため)
(注3)Ishwaran, H., Kogalur, U. B., Blackstone, E. H., & Lauer, M. S. 「Random survival forests」 The Annals of Applied Statistics, 2(3), 841-860 (2008)
https://projecteuclid.org/journals/annals-of-applied-statistics/volume-2/issue-3/Random-survival-forests/10.1214/08-AOAS169.full
Gradient Boosting Survival Tree (GBST)
勾配ブースティングを生存時間解析に適用したモデルです(注4)。複数の弱い学習器(決定木)を逐次的に組み合わせ、前の学習器の誤差を次の学習器で修正します。Cox比例ハザードモデルの部分尤度を損失関数として、勾配降下法で最適化を行います。
主な特徴:
- 逐次的な誤差補正により、予測精度の向上が期待できる
- ハイパーパラメータの調整により、柔軟なモデリングが可能
- 変数重要度を算出でき、モデルの解釈に活用できる
課題:
- 過学習のリスクがあり、正則化や学習率の慎重な調整が求められる
- 逐次的な学習のため、並列化が難しく計算時間がかかる場合がある
(注4)Pölsterl, S. 「scikit-survival: A Library for Time-to-Event Analysis Built on Top of scikit-learn」 Journal of Machine Learning Research, 21(212), 1-6 (2020)
https://jmlr.org/papers/v21/20-729.html
DeepSurv
ニューラルネットワークをベースとした深層学習モデルで、2016年にKatzmanらによって提唱されました(注5)。Coxモデルの線形部分をニューラルネットワークに置き換えた構造をとり、複雑な非線形関係を多層のニューロンで表現します。
主な特徴:
- 複雑な非線形関係を学習可能
- 高次元データや非構造化データ(テキスト、画像など)にも対応
- 表現学習により、元の変数から有用な特徴量を自動抽出
- 大規模データで真価を発揮
課題:
- 計算コストが高く、学習に時間がかかる
- ハイパーパラメータのチューニングが難しい
- 特に解釈性が低い(ブラックボックス化)
(注5)Katzman, J. L., Shaham, U., Cloninger, A., Bates, J., Jiang, T., & Kluger, Y. 「DeepSurv: Personalized Treatment Recommender System Using A Cox Proportional Hazards Deep Neural Network」 BMC Medical Research Methodology, 18(1), 24 (2018)
https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-018-0482-1
機械学習モデルの強みと課題
生存時間解析における機械学習モデルは、従来手法と比較して多くの強みを持つ一方で、いくつかの課題も存在します。以下では、それぞれの特徴を整理します。
強み:
非線形関係の捕捉
- 複雑な非線形関係や変数間の交互作用を自動的に学習
- 従来手法では見逃されていたパターンを発見できる可能性
高次元データへの対応
- 多数の説明変数を扱える(特徴量が数百〜数千に及ぶケース)
- 正則化手法により、重要な変数を自動的に選択
予測精度の向上
- ベンチマークデータセットでの実験では、従来手法を上回る精度を達成するケースが多い
- 特に、データ量が豊富な場合に優位性が顕著
柔軟性
- 画像、テキスト、時系列など、多様なデータ形式を統合的に扱える
- ドメイン知識を組み込みやすい(例:ニューラルネットワークの構造設計)
課題:
計算コストの高さ
- 学習に長時間を要する(特に深層学習)
- ハイパーパラメータのチューニングに試行錯誤が必要
- 大規模なデータセットでは、計算資源(GPUなど)が必要
解釈性の低さ(ブラックボックス問題)
- なぜその予測になったかを説明しにくい
- 医療や金融など、説明責任が求められる分野では課題
- 対策:SHAP値、LIME、Attention機構などの解釈手法を併用
過学習のリスク
- モデルが複雑すぎると、訓練データに過度に適合し、新しいデータでの予測性能が低下
- 対策:適切な正則化、クロスバリデーション、早期停止などのテクニックが必要
実装の難しさ
- 専門的な知識とスキルが必要
- ライブラリやツールは整備されつつあるが、従来手法に比べるとハードルが高い
実務での活用における考慮点
機械学習モデルを実務で活用する際は、以下の点を総合的に考慮する必要があります。
精度と解釈性のトレードオフ
- 単純なモデル(例:Coxモデル)は解釈しやすいが、予測精度で劣る可能性
- 複雑なモデル(例:DeepSurv)は高精度だが、説明が困難
- ビジネスの要件に応じて、適切なバランスを選択
計算リソースと時間の制約
- リアルタイム予測が必要な場合は、推論速度を重視
- バッチ処理で良い場合は、精度を優先
データの質と量
- サンプルサイズが小さい場合は、過学習を避けるため単純なモデルが望ましい
- 大規模データがある場合は、深層学習が真価を発揮
規制や説明責任
- 医療や金融など規制の厳しい分野では、解釈可能性が重視される
- マーケティングなど規制が緩い分野では、精度を優先しやすい
モデルのメンテナンス
- データの分布が時間とともに変化する場合、定期的な再学習が必要
- 運用体制(MLOps)の整備が重要
- データの分布が時間とともに変化する場合、定期的な再学習が必要
第3章:実践:生存時間解析モデルの構築と評価
3.1 データ概要
生存時間解析を実践する際、データの要素、データ準備におけるポイント、データの品質確保について理解することが重要です。以下では、これらの観点から解説します。
必須要素
- 観察開始時刻と終了時刻
- 各サンプルの観察期間を定義
- 例:健康診断受診日と追跡終了日、治療開始日と観察終了日
- イベント発生フラグ
- 観察期間中に目的の事象が発生したか(1)、打ち切りか(0)を示すバイナリ変数
- 例:疾病発症した(1)/ 未発症(0)、再発した(1)/ 寛解継続中(0)
- 説明変数(特徴量)
- 予測に用いる変数群
- 基本属性(年齢、性別、BMI、血圧など)
- 検査データ(血糖値、HbA1c、脂質項目、肝機能など)
- 生活習慣(喫煙、飲酒、運動習慣、既往歴など)
データ準備における重要なポイント
時間の原点の設定
- 生存時間解析では、「いつを時間ゼロとするか」の定義が重要
- 例:健康診断受診日、治療開始日、リスク因子が初めて検出された日など
- 原点の選び方により、解釈が大きく変わる可能性がある
時間スケールの選択
- 分析の目的に応じて適切な時間単位を選択(月、年など)
- 疾病発症予測では通常、月単位または年単位が用いられる
- あまりに細かい単位では、ノイズが多くなる
- あまりに粗い単位では、重要な変化を見逃す可能性がある
データの品質確保
データの品質が分析結果に大きく影響するため、以下の前処理が重要です。
- 欠損値の処理
- 欠損パターンの確認(MCAR、MAR、MNARの判別)
- 適切な補完方法の選択(平均値補完、多重代入法、モデルベース補完など)
- 欠損値が多い変数の除外判断
- 外れ値の検出と処理
- 統計的手法(IQR、Zスコアなど)による外れ値の特定
- ドメイン知識に基づく妥当性の検証(例:BMI 60以上、血圧300以上などの異常値)
- 外れ値の処理(除外、キャッピング、変換など)
- 変数の選択と変換
- 相関分析による多重共線性のチェック(例:BMIと体重- 身長の関係)
- ドメイン知識に基づく重要変数の選定
- 必要に応じた変数変換(対数変換、標準化、カテゴリ化など)
- 時間依存変数の扱い
- 時間とともに変化する変数(例:血糖値の推移、BMIの変化など)の適切なモデリング
- 治療介入などの影響を考慮した因果関係の解釈に注意が必要
3.2 モデル構築の実践例
生存時間解析では、RSF、GBST、DeepSurvなど複数の機械学習モデルが利用可能です。本稿では、予測精度と解釈性のバランスが良い勾配ブースティングサバイバルツリー(GBST)を例に、疾病発症予測モデルの構築の流れを解説します。
モデル構築の基本的な流れ
生存時間解析モデルの構築は、以下の手順で進めます。
- データの準備
- 目的変数(時間とイベントフラグ)と説明変数を適切な形式に整形
- 生存時間解析用のライブラリでは、構造化配列などの特殊な形式が必要な場合がある
- 訓練-検証-テストデータへの分割
- モデルの汎化性能を適切に評価するため、データを3つに分割
- イベント発生率を各セットで均等に保つよう、層化分割を実施
- ハイパーパラメータの探索
- n_estimators(決定木の数)、learning_rate(学習率)、max_depth(木の深さ)などを調整
- グリッドサーチやランダムサーチ、ベイズ最適化などを用いて最適化
- 検証データでのC統計量などの評価指標を最大化するハイパーパラメータを選択
- モデルの学習
- 最適化されたパラメータでモデルを訓練
- 訓練データでの過学習に注意しながら学習を進める
- 予測の実行
- 累積ハザード関数の推定(特定時点でのリスクスコアとして活用。値が大きいほどリスクが高い)
- 生存関数の推定(例:6カ月後、12カ月後の未発症確率)
実務における注意点
モデルを実務で運用する際には、以下の点に留意する必要があります。
計算リソースの管理
- GBSTの学習では、Cox部分尤度の最適化に全サンプル間の順序関係の計算が必要なため、計算コストが高い(O(n²))
- 大規模データでは学習時間が長くなるため、初期探索ではサンプリングデータや粗いグリッドサーチを活用
クロスバリデーションの設計
- 時系列データの場合、時系列クロスバリデーションの使用を検討
- 層化クロスバリデーションにより、各フォールドでイベント発生率を均等に保つ
モデルの保存と再利用
- 訓練したモデルは適切な形式で保存し、再利用可能にする
- モデルのバージョン管理を行い、再現性を確保
3.3 モデル評価とキャリブレーション
生存時間解析モデルの評価には、通常の分類・回帰モデルとは異なる指標が用いられます。打ち切りデータの存在や、時間軸を考慮した予測の特性を反映した評価が必要です。
統合的な評価の重要性
実務では、複数の評価指標を組み合わせて、モデルの性能を多角的に評価することが重要です。
- C統計量:全体的な識別能力を評価
- Time-Dependent AUC:時間的な安定性を確認
- キャリブレーション:予測確率の妥当性を評価
これらの指標を総合的に評価することで、モデルの実用性を多面的に判断できます。以下では、各指標について詳しく解説します。
C統計量(Concordance Index, C-index)による評価
C統計量は、生存時間解析における代表的な評価指標です。この指標は、「予測されたリスクの順序が実際の生存時間の順序とどの程度一致しているか」を測定します。
C統計量の解釈
- 値の範囲:0.5から1.0(理論的には0〜1だが、ランダム予測で0.5)
- 0.5:ランダムな予測と同等(予測能力なし)
- 1.0:完全な予測(全てのペアで順序が正しい)
- 実務での目安:
- 0.7〜0.8:一定の予測性能
- 0.8〜0.9:良好な予測性能
- 0.9以上:優れた予測性能(過学習の可能性にも注意)
計算方法の概念
C統計量は、全ての比較可能なペアについて、以下を評価します。- 2人の対象者AとBを考える
- Aの方が早く事象を経験した場合、モデルの予測リスクスコアもAの方が高いか測る
- このような「順序が一致したペア」の割合がC統計量
C統計量の限界
- 時間による予測性能の変化を捉えられない
- 予測の絶対的な精度(キャリブレーション)は評価できない
- 打ち切りが多い場合、比較可能なペアが少なくなり、推定が不安定になる可能性
Time-Dependent AUC(時間依存型AUC)
特定の時点 t における予測性能を評価する指標です。「時刻 t までに事象が発生するか否か」を二値分類問題として、各時点でのAUCを計算します。

出所: 大和総研作成
この図は、Time-Dependent AUCの概念を示す例です。横軸は時間(年)、縦軸はAUC値を表します。このような図を用いることで、モデルの予測性能が時間とともにどのように変化するかを視覚的に把握できます。例えば、短期予測(1-2年)と長期予測(8-10年)で性能が異なる場合、その傾向を確認できます。信頼区間(薄色の帯)を併せて表示することで、予測の安定性も評価できます。実務では、このような時系列での性能評価により、モデルがどの時間帯で信頼できる予測を提供しているかを判断する材料となります。
- 重要性
- モデルの予測性能は時間によって変化する可能性がある
- 短期的な予測は正確だが長期的には不正確、またはその逆のパターンを検出
- モデルの時間的な安定性を確認できる
AUCが時間とともに低下する場合は長期予測の精度に課題があり、不安定に変動する場合はモデルの汎化性能に問題がある可能性があります。
キャリブレーション(Calibration)
キャリブレーションは、「予測された確率が実際の発生率と一致しているか」を評価します。例えば、モデルが「発症確率60%」と予測した集団において、実際に60%程度が発症していれば、キャリブレーションが良好といえます。
ただし、C統計量やAUCが高くても、キャリブレーションが悪い場合があります(順序は正しいが絶対値が系統的にずれる)。例えば、「発症確率30%以上の人に介入する」といった閾値ベースの判断では、予測確率の絶対値が正確でなければ、過剰介入や介入漏れが発生します。このため、ビジネス上の意思決定には正確なキャリブレーションが不可欠です。
では、キャリブレーションをどのように評価すれば良いのでしょうか。視覚的評価と定量的評価という2つのアプローチで評価します。以下、それぞれについて説明します。
視覚的評価:キャリブレーションプロット
キャリブレーションプロットは、「予測された生存確率」と「実際の生存確率」の一致度を視覚化します。理想的には45度線上にプロットが並びます。
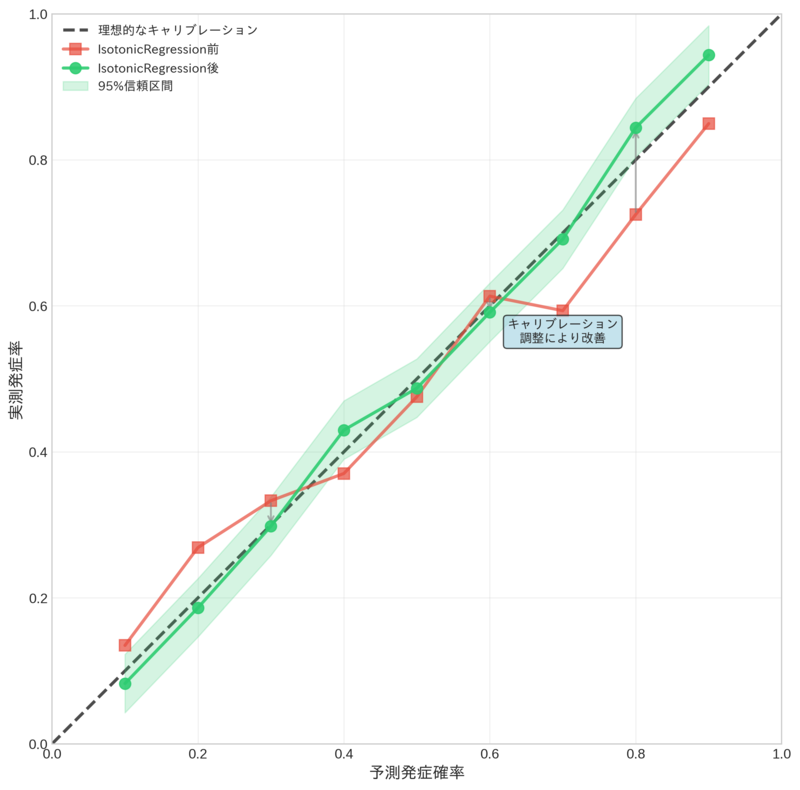
図7. IsotonicRegressionによるキャリブレーション改善(例) この図は、キャリブレーション調整の効果を示す例です。理想的なキャリブレーションでは、予測確率と実測発症率が45度線(黒破線)上に位置します。調整前(赤色のマーカー)では予測と実測にズレがある状態を示し、IsotonicRegression(単調回帰)による調整後(緑色のマーカー)では、予測が理想線に近づく様子を表現しています。灰色の矢印が調整による改善の方向を示しています。このように、キャリブレーション調整の前後を比較することで、調整手法の効果を視覚的に評価できます。
調整手法
- Platt Scaling:ロジスティック回帰を用いて予測スコアを確率に変換。実装が簡単で計算コストが低い
- Isotonic Regression:単調性を保ちながら、予測を実際の確率にマッピング。より柔軟だがサンプルサイズが小さいと過学習のリスク
定量的評価:Brierスコア
Brierスコアは、予測確率と実際の結果の差を測定する指標で、確率的な予測の精度を直接評価できます。値が小さいほど予測精度が高いことを示します(0〜1の範囲)。
Integrated Brier Score(IBS)は、複数の時点でのBrierスコアを統合した指標で、全体的なキャリブレーション性能を評価します。ベースラインモデルと比較することで、相対的な改善度を評価できます。
3.4 モデルの解釈性と実務での課題
変数重要度による解釈
GBSTでは、各変数がモデルの予測にどれだけ寄与しているかを定量化できます。変数重要度は、その変数が決定木の分岐でどれだけ使用され、どれだけ予測性能の向上に貢献したかを示します。
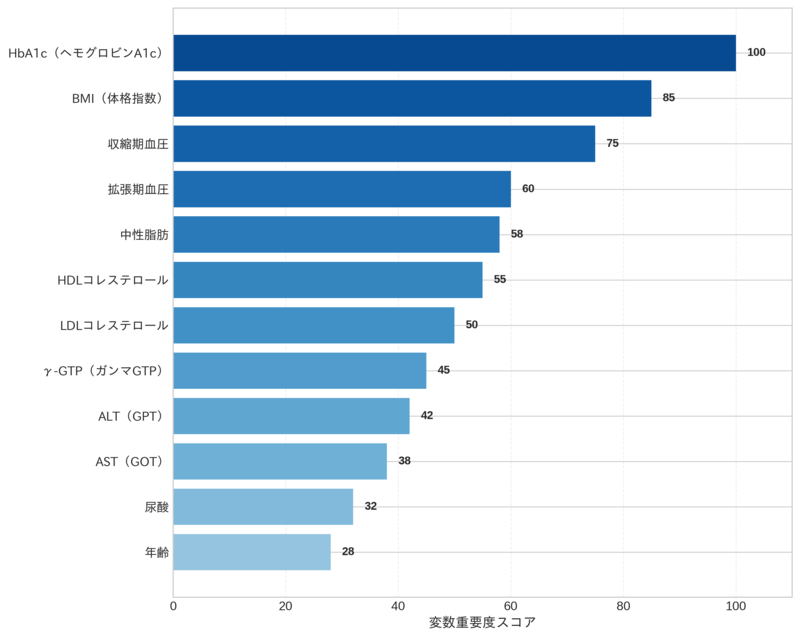
この図は、健康診断データを用いた疾病発症予測モデルにおける変数重要度の表示例です。変数重要度は、各健康指標が予測にどの程度寄与しているかを定量的に示します。この例では、血糖関連指標、体格指標、血圧、脂質、肝機能など、さまざまな健康指標の重要度を比較しています。実際のモデルでは、データや対象疾病によって重要な変数は異なりますが、このような可視化により、モデルの予測根拠を理解しやすくなります。
重要度が高い上位の変数に注目することで、医療専門家との議論や、保健指導プログラムの設計に活用できます。
リスクスコアの分布分析
モデルが予測したリスクスコア(累積ハザード)の分布を、発症群と未発症群で比較することで、モデルの識別能力を視覚的に確認できます。
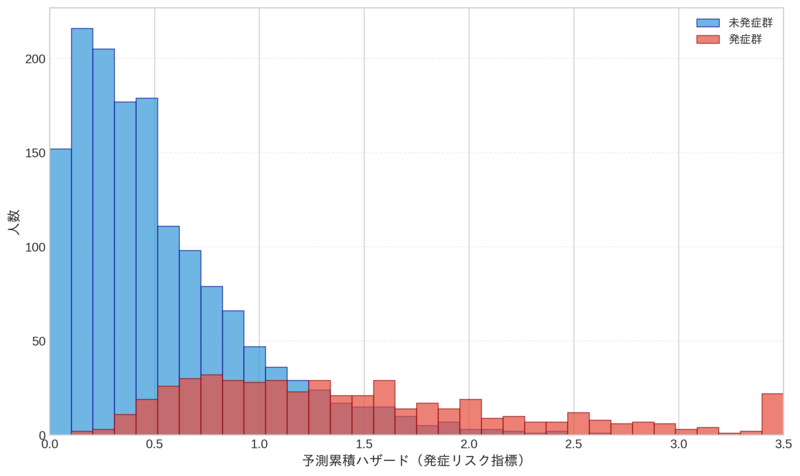
この図は、発症群(赤)と未発症群(青)の予測累積ハザードの分布をヒストグラムで示す例です。横軸は累積ハザード(発症リスク指標)で表されます。一般的に、発症群は高い累積ハザード値に分布が偏り、未発症群は低い値に集中する傾向があります。両群の分布が明確に分離していれば、モデルが適切にリスクを識別できていることを示します。累積ハザードは、例えば1.5の場合、約78%の発症確率(1 - exp(-1.5))に相当します。このように、従来の0-100のリスクスコアではなく、累積ハザード単位で表現することで、生存時間解析の理論に即した解釈が可能となります。実務では、この分布を参考に適切な介入閾値を設定したり、対象者数を推定したりできます。
実務への応用と主な課題
生存時間解析モデルを実務に適用する際には、変数重要度やリスクスコアの分布分析といった解釈手法を活用しながら、データ品質、モデルの汎化性能、倫理的配慮、運用体制といった課題にも対処する必要があります。以下では、具体的な応用方法と課題を整理します。
変数重要度の実務応用
- ハイリスク者の特定:どの健康指標が発症リスクに影響するかを把握
- 介入施策の優先順位付け:改善すべき指標を明確化
- データ収集の最適化:重要な変数に焦点を当てた効率的なデータ収集
リスクスコア分布分析の実務応用
- 介入閾値の設定:分布を参考に、適切なリスク閾値を決定
- 介入対象者の推定:閾値以上の人数を把握し、リソース配分を計画
- モデルの妥当性確認:両群の分離が不十分な場合、モデルの改善が必要
データ品質の確保
- 欠損値や外れ値の適切な処理
- データ収集プロセスの標準化
- 長期的な追跡調査の継続性確保
モデルの汎化性能
- 異なる集団(年齢層、地域など)への適用可能性
- 時間経過によるデータ分布の変化(ドリフト)への対応
- 定期的なモデルの再学習とパフォーマンス監視
倫理的・法的配慮
- 個人情報保護とプライバシーの確保
- モデルの予測結果を意思決定に使用する際の説明責任
- バイアスや差別的な予測の回避
運用体制の整備
- データの継続的な更新と品質管理
- モデルのバージョン管理と再現性の確保
- 専門家(医師、保健師など)との連携体制構築
これらの課題に適切に対処することで、生存時間解析モデルを実務に効果的に導入できます。
第4章:今後の展望
4.1 技術的な進化の方向性
生存時間解析における機械学習の応用は、打ち切りデータや時間軸を含む予測という固有の課題に対し、新たな技術的アプローチによって解決の可能性を広げています。
深層学習による複雑なパターン学習
Transformerアーキテクチャを生存時間解析に適用する研究により、時間変化する共変量(健診値の経年変化など)と打ち切りパターンの複雑な関係を学習できる可能性が示されています。複数のモダリティ(検査値、画像、問診票)を統合した予測モデルの構築により、従来のCoxモデルでは捉えきれなかった非線形な時間依存構造の抽出が期待されます。
因果推論による介入効果の評価
「どの時点で介入すれば最も効果的か」という問いに答えるため、因果推論の手法と生存時間解析を組み合わせる研究が進んでいます。反事実的推論により「介入しなかった場合の生存曲線」を推定することで、治療介入や生活習慣改善プログラムが生存時間に与える効果を、交絡因子の影響を除いて定量化できます。
リアルタイムデータによる動的予測
ウエアラブルデバイスから得られる連続的な生体データを用いて、ハザード関数を動的に更新する手法の研究が進んでいます。個人の状態変化に応じてリスク評価が更新されることで、ハザードが急上昇した時点での介入を可能にする仕組みの実現が目指されています。
自動化による実務適用の促進
生存時間解析に用いられる多様なモデル(Random Survival Forest、GBST、DeepSurvなど)の自動選択や、C統計量、Integrated Brier Scoreといった評価指標の最適化を自動化する取り組みが進んでいます。ただし、医療分野ではハザード比や生存曲線といった解釈可能な出力が求められるため、説明可能性を損なわない自動化の設計が重要です。
第5章:大和総研の取り組みの方向性
大和総研では、生存時間解析と機械学習の融合を、金融分野に加え、健康経営・人的資本経営における重要な技術基盤として位置付け、その応用可能性を探索しています。健康経営・人的資本経営の文脈では、疾病発症予測などの医療分野と、従業員のウェルビーイングと生産性向上に向けたデータ分析やAI技術の活用といった人事分野の両面で、統合的なアプローチの実現を目指しています。
特に重視するのは、単なる予測精度の追求ではなく、解釈可能性と実務での運用性を兼ね備えたソリューションの提供です。金融や医療といった規制の厳しい分野では「なぜその予測になったのか」を説明できることが不可欠であり、解釈手法の活用、専門家との協働、運用体制の整備を通じて、技術の高度化と説明責任の両立を図る方針です。
その具体的な取り組みのひとつとして、従業員の健康リスク予測と予防的介入のタイミング最適化に向けて、生存時間解析技術をウェルビーイングプラットフォーム「Hearbit(ハービット)」へ統合する検証を進めています。Hearbitは、従業員一人ひとりによりそう健康管理アプリと、企業や健康保険組合向けに人的資本経営を支えるダッシュボード「Hearbit View(ハービットビュー)」から構成され、エンゲージメントと生産性をウェルビーイングで支えるサービスです。
大和総研は、先進的な技術と実務知見を融合させ、お客様が安心してデータ駆動型の意思決定を行えるよう支援してまいります。
おわりに
生存時間解析は、「いつ、何が起こるか」という時間軸を含む予測を可能にする手法です。本稿では、打ち切りデータを統計的に適切に扱う生存時間解析の基礎から、機械学習との融合による予測精度の向上、そして実務での応用可能性まで解説してきました。
従来のCox比例ハザードモデルが持つ線形性や比例ハザード性の仮定を超え、勾配ブースティングや深層学習を用いることで、複雑な非線形関係や時間依存構造を捉えることが可能になりました。C統計量やTime-Dependent AUC、キャリブレーションといった評価指標により、モデルの予測性能と実用性を多面的に検証できます。時間軸上でのリスク変化を捉える生存時間解析の特性は、予防的介入のタイミング最適化や動的なリスク管理において、従来手法にはない価値を提供します。
生存時間解析や機械学習の活用にご関心をお持ちの方は、ITソリューションサービスサイトよりお問い合わせください。
参考文献
- Cox, D. R. (1972). "Regression Models and Life-Tables." Journal of the Royal Statistical Society: Series B (Methodological), 34(2), 187-220.
- Kaplan, E. L., & Meier, P. (1958). "Nonparametric Estimation from Incomplete Observations." Journal of the American Statistical Association, 53(282), 457-481.
- Ishwaran, H., Kogalur, U. B., Blackstone, E. H., & Lauer, M. S. (2008). "Random Survival Forests." The Annals of Applied Statistics, 2(3), 841-860.
- Pölsterl, S. (2020). "scikit-survival: A Library for Time-to-Event Analysis Built on Top of scikit-learn." Journal of Machine Learning Research, 21(212), 1-6.
- Pölsterl, S., Navab, N., & Katouzian, A. (2015). "Fast Training of Support Vector Machines for Survival Analysis." Proceedings of ECML PKDD 2015.
- Katzman, J. L., Shaham, U., Cloninger, A., Bates, J., Jiang, T., & Kluger, Y. (2018). "DeepSurv: Personalized Treatment Recommender System Using A Cox Proportional Hazards Deep Neural Network." BMC Medical Research Methodology, 18(1), 24.
- Simon, N., Friedman, J., Hastie, T., & Tibshirani, R. (2011). "Regularization Paths for Cox's Proportional Hazards Model via Coordinate Descent." Journal of Statistical Software, 39(5), 1-13.
- Wang, Z., Sun, J., & Karargyris, A. (2022). "SurvTRACE: Transformers for Survival Analysis with Competing Events." arXiv preprint arXiv:2110.00855.
- Harrell, F. E., Califf, R. M., Pryor, D. B., Lee, K. L., & Rosati, R. A. (1982). "Evaluating the Yield of Medical Tests." JAMA, 247(18), 2543-2546.
- Uno, H., Cai, T., Pencina, M. J., D'Agostino, R. B., & Wei, L. J. (2011). "On the C‐statistics for Evaluating Overall Adequacy of Risk Prediction Procedures with Censored Survival Data." Statistics in Medicine, 30(10), 1105-1117.
- Graf, E., Schmoor, C., Sauerbrei, W., & Schumacher, M. (1999). "Assessment and Comparison of Prognostic Classification Schemes for Survival Data." Statistics in Medicine, 18(17‐18), 2529-2545.
本稿は2025年10月時点の情報に基づいています。技術の進展や実務環境の変化により、内容が更新される可能性があります。